









Serverless computing, commonly known as Serverless, has become a buzzword in the cloud-native field. It will fuel the next wave of development in cloud computing after IaaS and PaaS. Serverless emphasizes an architecture philosophy and service model that allows developers to focus on implementing business logics in applications rather than on managing infrastructures (e.g., servers). In its paper Cloud Programming Simplified: A Berkeley View on Serverless Computing, the University of California at Berkeley presents two key viewpoints on Serverless:
- Although server-based computing will be here to stay, its importance will decrease as Serverless computing continues to mature.
- Serverless computing will eventually become the paradigm of the cloud computing age, replacing the server-based computing model to a great extent and putting an end to the Client-Server age.
Now, what is Serverless?
Introduction to Serverless
On Serverless, the University of California at Berkeley also gave a clear definition in the above-mentioned paper: Serverless computing = FaaS + BaaS. Conventionally, cloud services are classified from bottom to top layer as Hardware, Base Cloud Platform, PaaS, and Applications according to the degree of abstraction. Nevertheless, the ideal state of the PaaS layer is to have the capability of Serverless. Thus, let's replace the PaaS layer with Serverless, which is indicated by the yellow part in the following figure.
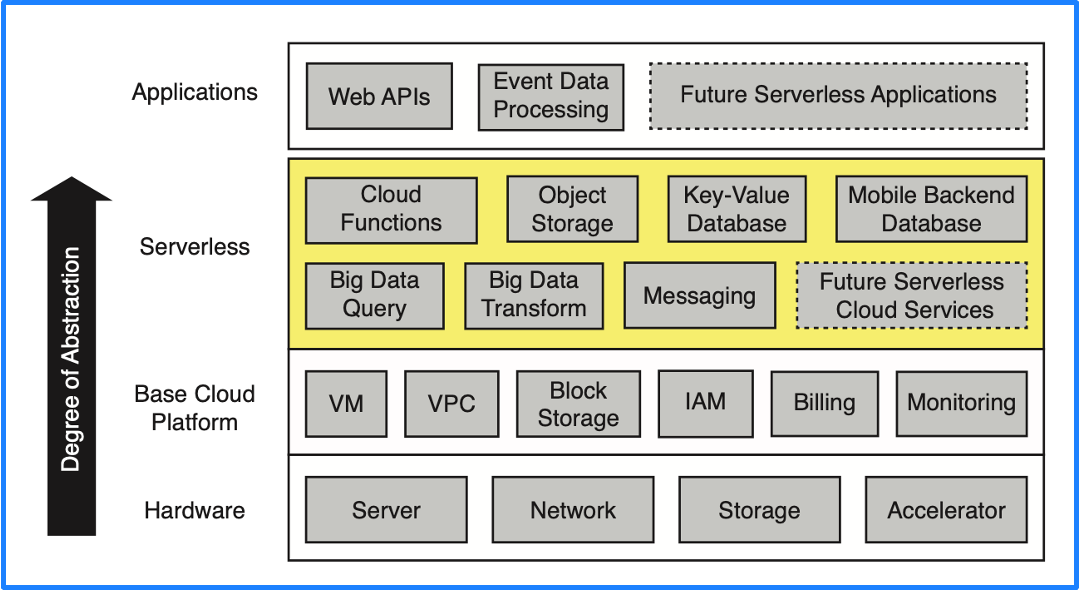
Serverless consists of two components, BaaS and FaaS. Base cloud services, including object storages, relational databases, and message queue (MQ), are essential for every cloud provider and belong to BaaS (Backend-as-a-Service). FaaS (Function as a Service) is the core of Serverless.
Analysis of Existing Open-Source Serverless Platforms
The KubeSphere community has been conducting in-depth researches on Serverless since late 2020. We found that:
- Most existing open-source FaaS projects were initiated earlier than the emergence of Knative.
- An outstanding Serverless platform as it is, Knative is still working its way towards a FaaS platform because Knative Serving can run only applications rather than functions.
- Knative Eventing is an excellent event management framework, but its design is too complex and users could face a steep learning curve.
- OpenFaaS is a popular FaaS project, but its technology stack is rigid as it depends on Prometheus and Alertmanager for autoscaling.
- In recent years, many outstanding open-source projects (such as KEDA, Dapr, Cloud Native Buildpacks (CNB), Tekton, and Shipwright) have emerged in the cloud-native Serverless-related fields, laying a foundation for building a next generation open-source FaaS platform.
To sum up, we have come to the conclusion that the existing open-source Serverless or FaaS platforms cannot meet the demands for building a modern cloud-native FaaS platform, while the latest advances in the cloud-native Serverless field make it possible to build a next generation FaaS platform.
Framework Design of a Next Generation FaaS Platform
If we were to design a modern FaaS platform, what would its architecture look like? The ideal FaaS framework should be divided into several important parts according to the lifecycle of a function, namely, function framework, function building, function serving, and event-driven framework.
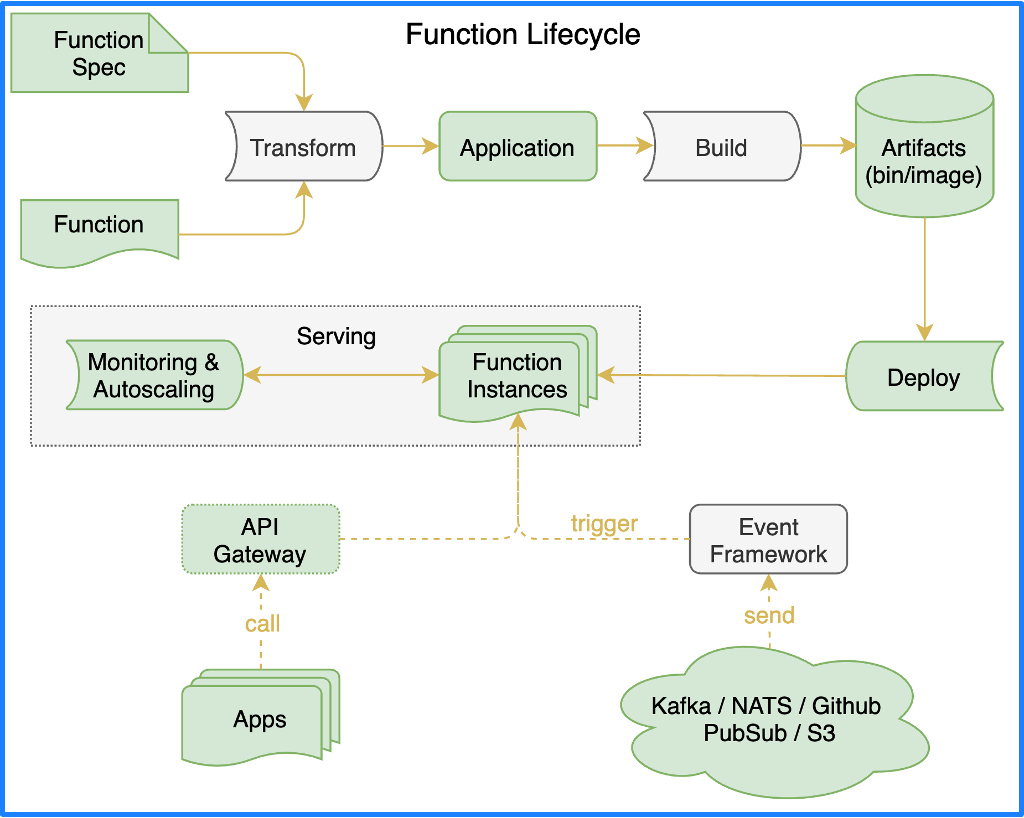
When it comes to FaaS, a Function Spec defines how functions should be written; then, functions need to be converted to applications, which is done by a function framework. Container images need to be built so that the applications can run in a cloud-native environment, which is done by a function building. Once the container images are built, these applications can be deployed to the runtime of function serving to serve external accesses.
Next, let's focus on the architecture design of function framework, function building, and function serving.
Function framework
To make it easier to learn function specifications during development, we need to add a mechanism to transform function code to ready-to-run applications. This mechanism needs to be implemented by making a general-purpose main function that handles incoming requests through the serving url function.
The main function contains a number of steps: one for associating user-submitted code, and the rest for common functionalities (such as context processing, event source handling, exception handling, port processing, etc.).
During the process of building a function, the builder uses the main function template to render user code, and then builds the main function in the container image.
Let's look at an example. Assuming we have the following function code:
package hello
import (
"fmt"
"net/http"
)
func HelloWorld(w http.ResponseWriter, r *http.Request) {
fmt.Fprint(w, "Hello, World!\n")
}
After being converted by the function framework, the following application code will be generated:
package main
import (
"context"
"errors"
"fmt"
"github.com/OpenFunction/functions-framework-go/functionframeworks"
ofctx "github.com/OpenFunction/functions-framework-go/openfunction-context"
cloudevents "github.com/cloudevents/sdk-go/v2"
"log"
"main.go/userfunction"
"net/http"
)
func register(fn interface{}) error {
ctx := context.Background()
if fnHTTP, ok := fn.(func(http.ResponseWriter, *http.Request)); ok {
if err := functionframeworks.RegisterHTTPFunction(ctx, fnHTTP); err != nil {
return fmt.Errorf("Function failed to register: %v\n", err)
}
} else if fnCloudEvent, ok := fn.(func(context.Context, cloudevents.Event) error); ok {
if err := functionframeworks.RegisterCloudEventFunction(ctx, fnCloudEvent); err != nil {
return fmt.Errorf("Function failed to register: %v\n", err)
}
} else if fnOpenFunction, ok := fn.(func(*ofctx.OpenFunctionContext, []byte) ofctx.RetValue); ok {
if err := functionframeworks.RegisterOpenFunction(ctx, fnOpenFunction); err != nil {
return fmt.Errorf("Function failed to register: %v\n", err)
}
} else {
err := errors.New("unrecognized function")
return fmt.Errorf("Function failed to register: %v\n", err)
}
return nil
}
func main() {
if err := register(userfunction.HelloWorld); err != nil {
log.Fatalf("Failed to register: %v\n", err)
}
if err := functionframeworks.Start(); err != nil {
log.Fatalf("Failed to start: %v\n", err)
}
}
Before the application is started, the function is registered as an HTTP function, a CloudEvent function, or an OpenFunction function. When the registration is completed, functionframeworks.Start is invoked to start the application.
Build
Once we have an application, we also need to build it into a container image. Kubernetes has deprecated dockershim and no longer uses Docker as the default container runtime. Thus, we cannot build container images through Docker-in-Docker in a Kubernetes cluster. Is there any other options for building images? How can we manage pipelines for building images?
Tekton is an excellent pipeline tool that originally was a Knative subproject and later donated to the Continuous Delivery Foundation. Tekton's pipeline logic is quite intuitive and can be divided into three steps: pulling code, building images, and pushing images. Each step is defined as a Task in Tekton, and all the Tasks form into a pipeline.
There are several tools for building container images, such as Kaniko, Buildah, BuildKit, and Cloud Native Buildpacks (CNB). The first three of them rely on Dockerfiles to build container images, while CNB is the latest technology emerging from the cloud-native field. Sponsored by Pivotal and Heroku, CNB, instead of relying on Dockerfiles, automatically detects the code to be built and generates OCI-compliant container images. This is an astonishing technology that has been adopted by Google Cloud, IBM Cloud, Heroku, and Pivotal. For example, many of the images on Google Cloud are built with CNB.
With these available image building tools, how can we let users select and switch at will between these tools during function building? That entails another project, Shipwright, an open-source project by Red Hat and IBM. It is dedicated to building container images in a Kubernetes cluster, and is donated to the CD Foundation. With Shipwright, you can flexibly switch between the four image building tools mentioned above as it provides a unified API interface that packages different building methods.
Let's look at an example of how Shipwright works. Assuming we have a manifest of a custom resource Build :
apiVersion: shipwright.io/v1alpha1
kind: Build
metadata:
name: buildpack-nodejs-build
spec:
source:
url: https://github.com/shipwright-io/sample-nodejs
contextDir: source-build
strategy:
name: buildpacks-v3
kind: ClusterBuildStrategy
output:
image: docker.io/${REGISTRY_ORG}/sample-nodejs:latest
credentials:
name: push-secret
The manifest contains 3 sections:
sourceindicates where to get the source code.strategyspecifies the tool for building images.outputindicates the image repository to which the image built from the source code is pushed.
strategy is configured by the custom resource ClusterBuildStrategy. For example, if we are going to use buildpacks to build an image, the ClusterBuildStrategy should look as follows:

It contains two steps. One is to prepare the environment, and the other to build and push the image. Each step is a Tekton Task managed by a Tekton pipeline.
Thus, Shipwright abstracts the ability to build images. Users can build images through a unified API, and switch between different image building tools by writing different strategy.
Serving
Serving refers to how functions/applications run with the ability to scale automatically (Autoscaling), either being event-driven or traffic-driven. The CNCF Serverless Whitepaper defines four function invocation types:
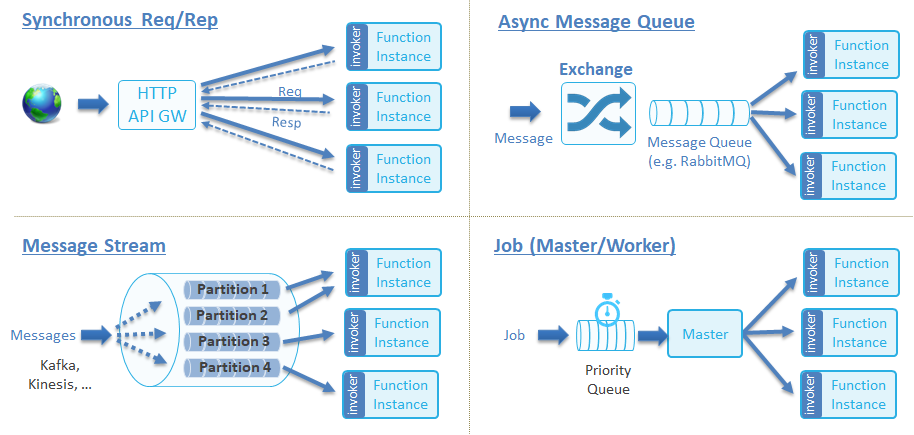
These four types can be summarized as follows:
- Synchronous function: A client must initiate an HTTP request, and the function won't return until it finishes its execution and gets the result.
- Asynchronous function: Once a request is initiated, the function returns before it finishes its execution. The result is notified to the invoker through events, such as Callback or MQ notifications, which is considered as event-driven.
Synchronous functions and asynchronous functions have different runtimes for their respective implementation:
- As for synchronous functions, Knative Serving is an excellent synchronous function runtime with powerful autoscaling capabilities. In addition to Knative Serving, synchronous function runtime can also be realized based on the combination of KEDA http-add-on and Kubernetes-native Deployments. This combination can remove the dependence on Knative Serving.
- As for asynchronous functions, implementation can be achieved with KEDA and Dapr. KEDA automatically scales the replica number of Deployments based on monitoring metrics of event sources; Dapr provides functions with the ability to access middlewares such as MQ.
Besides, Knative and KEDA have different capabilities in terms of autoscaling. Let’s look into it.
Knative autoscaling
Knative Serving has 3 main components: Autoscaler, Serverless, and Activator. Autoscaler gets metrics (e.g. concurrency) of a workload. If the concurrency is 0, the replica number of Deployment is scaled to 0. However, the function cannot be invoked after the replica number is scaled to 0. Therefore, Knative directs the entry point for invoking the function to Activator before the replica number is scaled to 0.
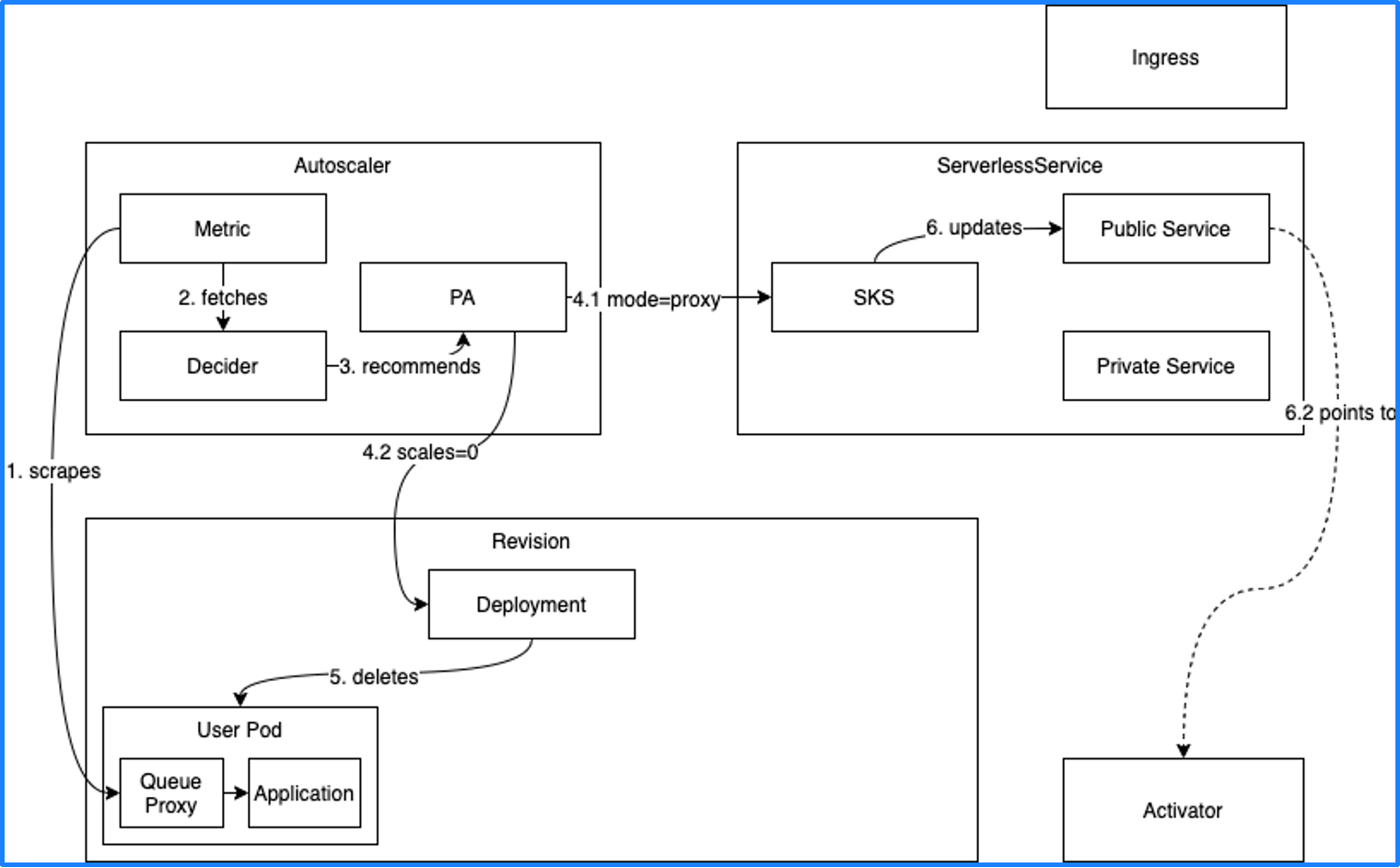
When new traffic comes in, it hits the Activator first, and the Activator notifies the Autoscaler to scale the replica number of Deployment to 1. Finally, the Activator forwards the traffic to the actual Pod to implement a service invocation. This process is also known as a cold start.

Thus, Knative can only rely on the traffic metrics of RESTful HTTP to scale automatically. In fact, many other metrics in practical use cases can also serve as the basis for autoscaling, such as Kafka message backlog. If the message backlog is getting excessive, more replicas are needed to process these messages. To realize autoscaling based on more metric types, we could use KEDA.
KEDA autoscaling
KEDA needs to work with Kubernetes HPA to achieve advanced capabilities of autoscaling. In other words, the combination of KEDA and HPA can implement the autoscaling from 0 to N, whereas HPA can implement the autoscaling only from 1 to N and KEDA only from 0 to 1.
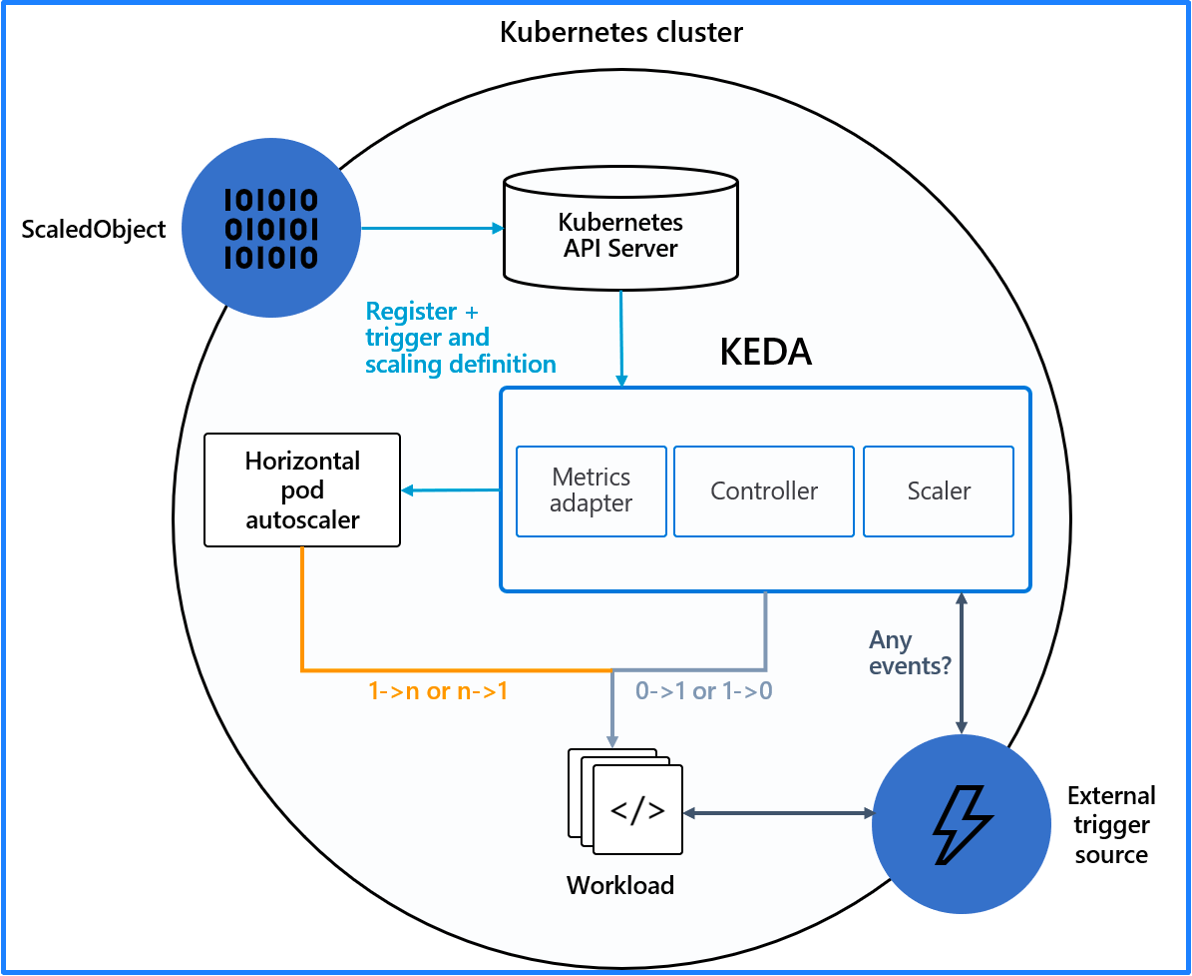
KEDA can implement autoscaling based on a number of metric types:
- Basic metrics of cloud services, such as those related to AWS and Azure.
- Linux system metrics, such as CPU and memory.
- Metrics of protocols specialized for open-source components, such as Kafka, MySQL, Redis, and Prometheus.

For example, you need the following manifest to implement autoscaling based on Kafka metrics:
apiVersion: keda.k8s.io/v1alpha1
kind: ScaledObject
metadata:
name: kafka-scaledobject
namespace: default
labels:
deploymentName: kafka-consumer-deployment # Name of the deployment to be scaled.
spec:
scaleTargetRef:
deploymentName: kafka-consumer-deployment # Name of the deployment to be scaled.
pollingInterval: 15
minReplicaCount: 0
maxReplicaCount: 10
cooldownPeriod: 30
triggers:
- type: kafka
metadata:
topic: logs
bootstrapServers: kafka-logs-receiver-kafka-brokers.default.svc.cluster.local
consumerGroup: log-handler
lagThreshold: "10"
The replicas scale between 0 and 10 as the metrics are checked every 15 seconds. Once the replicas are scaled, it has to wait for another 30 seconds before another autoscaling.
In addition, a trigger is defined, namely, the "logs" topic in a Kafka server. The message backlog threshold is 10, which means the instance number of logs-handler increases when the number of messages exceeds 10. If there is no message backlog, the instance number is scaled to 0.
Compared to implementing autoscaling based on HTTP traffic metrics, implementing autoscaling based on metrics of component-specialized protocols is more reasonable and flexible.
Although KEDA does not support autoscaling based on HTTP traffic metrics, it can be achieved through KEDA http-add-on that is a plug-in still in Beta stage. We will pay close attention to the project, and use it, when it matures, as the synchronous function runtime to replace Knative Serving.
Dapr
Nowadays, applications are mostly distributed with each application having different capabilities. To abstract the common functionality from different applications, Microsoft has developed a Distributed Application Runtime (Dapr). Dapr abstracts the common functionality from different applications into components. Different components are responsible for different functions, such as inter-service invocation, state management, resource binding for I/O, observability, etc. These distributed components are exposed to various programming languages through a same API.
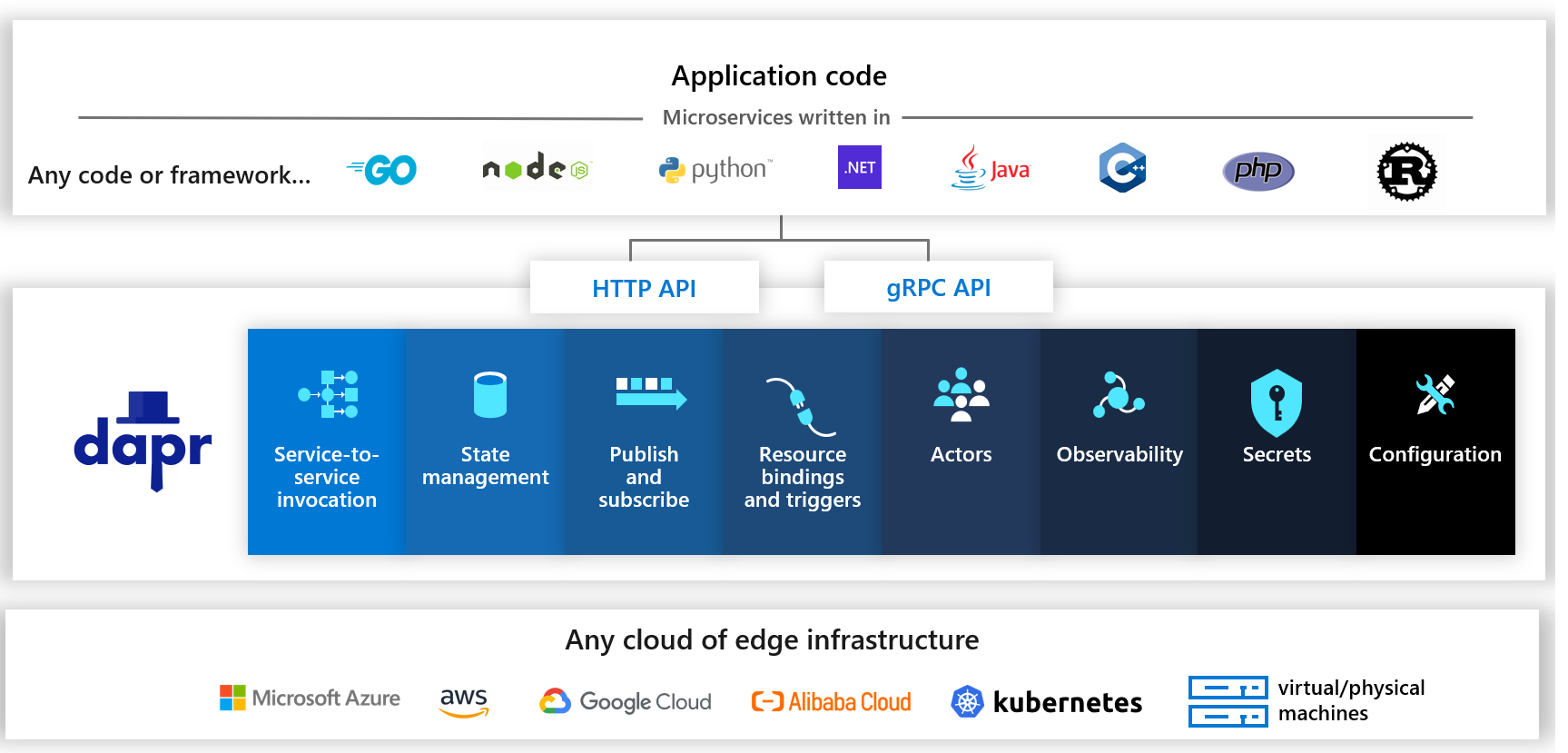
Function computing is also a kind of distributed application that uses a variety of programming languages. For example, to let a function communicate with Kafka, Golang needs to use Go SDK, Java needs to use Java SDK, and so on. You have to write different implementations for accessing Kafka with different languages. I believe I'm not the only person who think this is troublesome.
Assuming that you have to access many other MQ components in addition to Kafka, that's even more troublesome. Why? How many implementations will be needed for accessing 10 MQ with 5 languages? 50 implementations! With Dapr, 10 MQ will be abstracted as a method, namely, HTTP/GRPC interface. Now, only 5 implementations are required, which greatly reduces the amount of work to develop distributed applications.
Thus, Dapr is suitable for function computing platforms.
OpenFunction: a Modern Cloud-Native Serverless Computing Platform on Kubernetes
Based on researches on the technologies mentioned above, an open-source project named OpenFunction came into being. Its architecture is shown in the following figure.
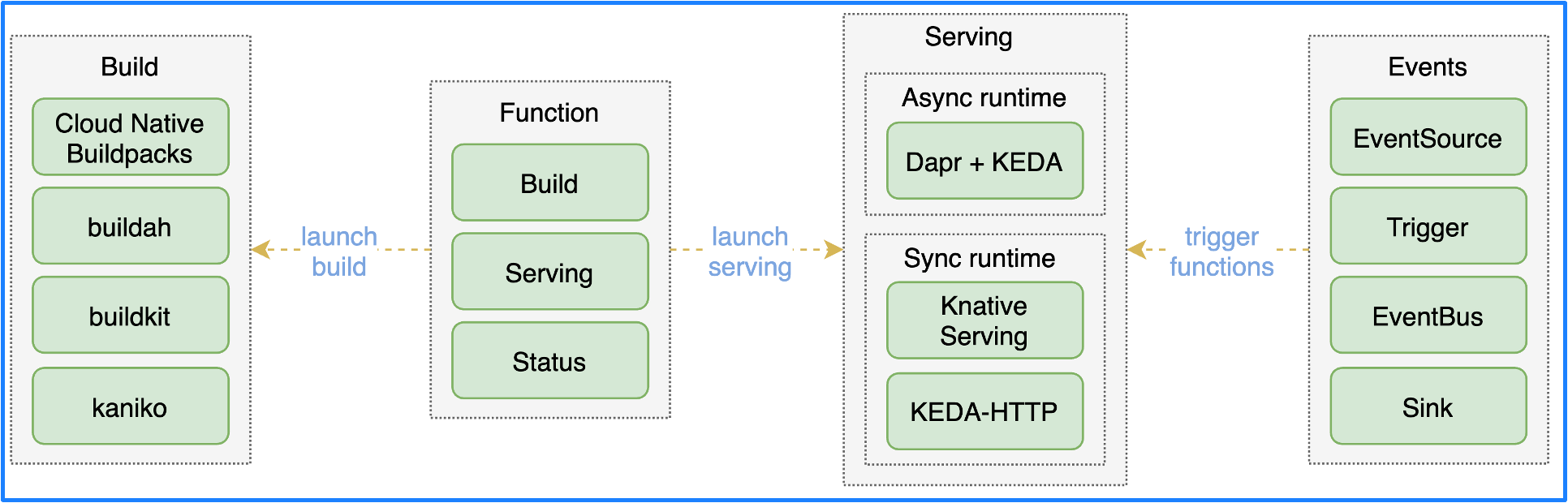
There are 4 main components:
Function: converts functions to applications.
Build: builds applications into container images by using Shipwright to switch between different image building tools.
Serving: deploys applications to different runtimes through Serving CRDs and supports the selection of synchronous or asynchronous runtime. Synchronous runtime can be supported through Knative Serving or KEDA-HTTP, while asynchronous runtime is supported through Dapr+KEDA.
Events: provides the ability to manage events for event-driven functions. Since Knative event management is too complex, we developed a new event management driver called OpenFunction Events.
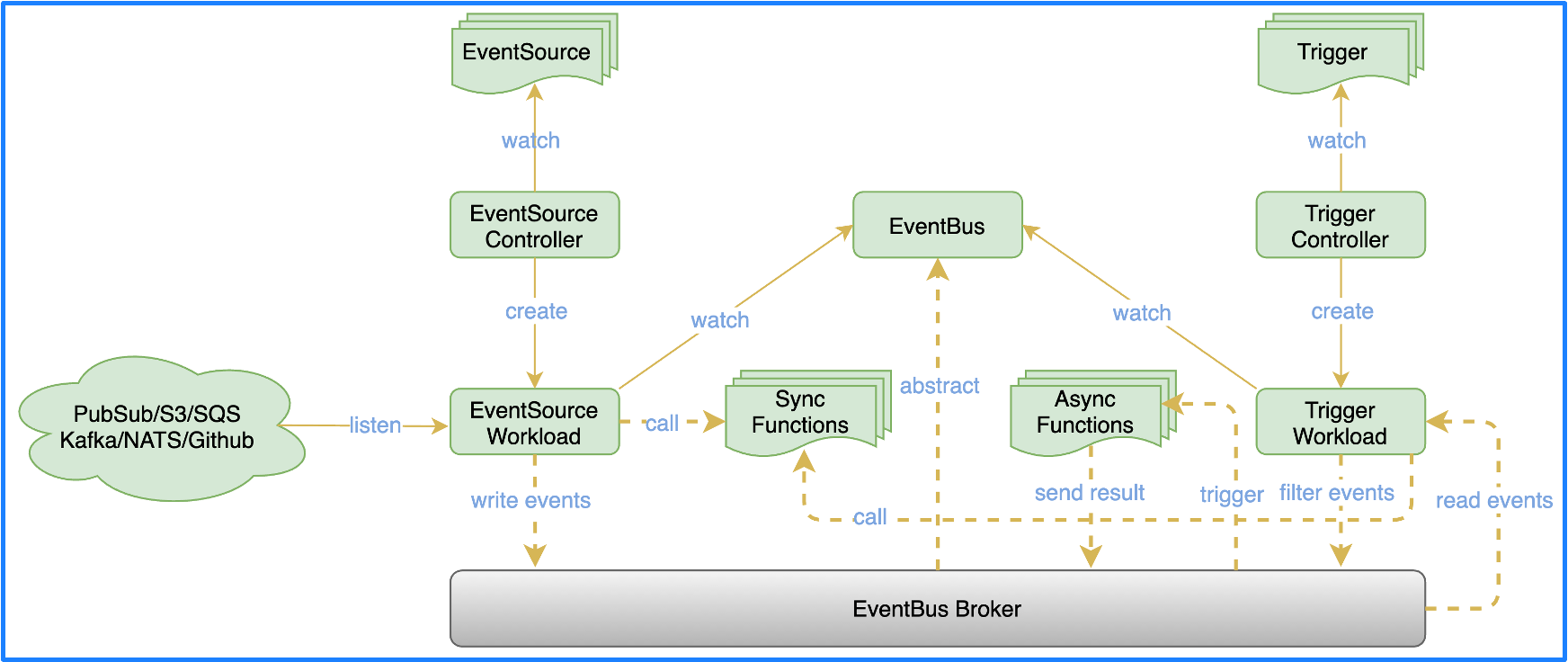
OpenFunction Events draws on some Argo Events design and also introduces Dapr. The overall architecture is divided into 3 parts:
- EventSource: an interface, which is implemented by asynchronous functions, for a variety of event sources to automatically scale based on the metrics of the event sources, making event consumption more resilient.
- EventBus:
EventBusuncouples EventBus from the specific Message Broker at the bottom layer through the capability of Dapr. You can integrate various MQ. There are two ways to handle an event consumed byEventSource. One is to invoke the synchronous function and waiting for the function to return the result; the other is to write it intoEventBusto trigger an asynchronous function when EventBus receives the event. - Trigger:
Triggerfilters various events through different expressions inEventBus, and writes them intoEventBusto trigger another asynchronous function.
Want to have a look at the practical use cases for OpenFunction? Refer to Serverless Use Case: Elastic Kubernetes Log Alerts with OpenFunction and Kafka.
OpenFunction Roadmap

OpenFunction released its very first version in May 2021. It has supported asynchronous functions since v0.2.0, added OpenFunction Events with Shipwright supported since v0.3.1, and added a CLI since v0.4.0.
OpenFunction is planning to introduce a visual interface, support more EventSource and the ability to process edge loads, and accelerate cold start by using WebAssembly as a lightweight runtime and combining the Rust function.
Join the OpenFunction Community
We welcome developers to the OpenFunction community. You can raise any queries, design suggestions, and cooperation proposals regarding OpenFunction.
Want to get involved? Fork OpenFunction or join us on Slack!
