









知识点
- 定级:中级
- 运维部署架构图如何画?
- 架构设计方案如何写?
- 部署节点如何规划?
- 成本如何分析计算?
简介
架构概要说明
今天分享一个实际小规模生产环境部署架构设计的案例,该架构设计概要说明如下:
- 本架构设计适用于中小规模(<=50)的 Kubernetes 生产环境,大型环境没有经验,有待验证。
- 所有节点采用云上虚拟机的方式部署,出于某些原因所有组件均自建,没有使用云上产品(有条件建议使用云上产品)。
- 本架构设计不包含安全设备,不包含 Kubernetes 安全配置,安全要求高的环境不适用。
- 本架构设计属于第一版, 也是我在 Kubernetes 生产集群架构设计实践之路上走出的第一步,难免有一些不合理的地方(欢迎各位指正),后续会根据线上遇到的问题持续进行优化改进。
- 本架构设计是基于 KubeSphere 部署的 Kubernetes,后续的很多功能实现都依托于 KubeSphere。
- 本架构设计时使用的当时最新的软件版本,拿到目前来看也有一定的参考意义,完全可以直接套用,换一下软件版本即可(具体怎么换,请看下文)。
本文只介绍选型分析、部署架构图、部署架构设计说明、部署节点规划、上云总成本分析等内容,具体的安装部署暂不涉及。
选择 KubeSphere 的理由
KubeSphere 是在 Kubernetes 之上构建的以应用为中心的多租户容器平台,提供全栈的 IT 自动化运维的能力,简化企业的 DevOps 工作流。
KubeSphere 提供了运维友好的向导式操作界面,帮助企业快速构建一个强大和功能丰富的容器云平台。
完全开源,通过 CNCF 一致性认证的 Kubernetes 平台,100% 开源,由社区驱动与开发。
安装简单,使用简单,支持部署在任何基础设施环境,提供在线与离线安装,支持一键升级与扩容集群。
功能丰富,在一个平台统一纳管 DevOps、云原生可观测性、服务网格、应用生命周期、多租户、多集群、存储与网络。
模块化 & 可插拔,平台中的所有功能都是可插拔与松耦合,您可以根据业务场景可选安装所需功能组件。
具备构建一站式企业级的 DevOps 架构与可视化运维能力(省去自己用开源工具手工搭积木)。
提供从平台到应用维度的日志、监控、事件、审计、告警与通知,实现集中式与多租户隔离的可观测性。
简化应用的持续集成、测试、审核、发布、升级与弹性扩缩容。
为云原生应用提供基于微服务的灰度发布、流量管理、网络拓扑与追踪。
提供易用的界面命令终端与图形化操作面板,满足不同使用习惯的运维人员。
可轻松解耦,避免厂商绑定。
除了上面的 10 条理由以外,更主要的是同类产品中 KubeSphere 属于最能打的,其它竞品在当年(2021 年)或多或少都有一些问题,无法走进我的心里。
部署架构设计
部署架构图
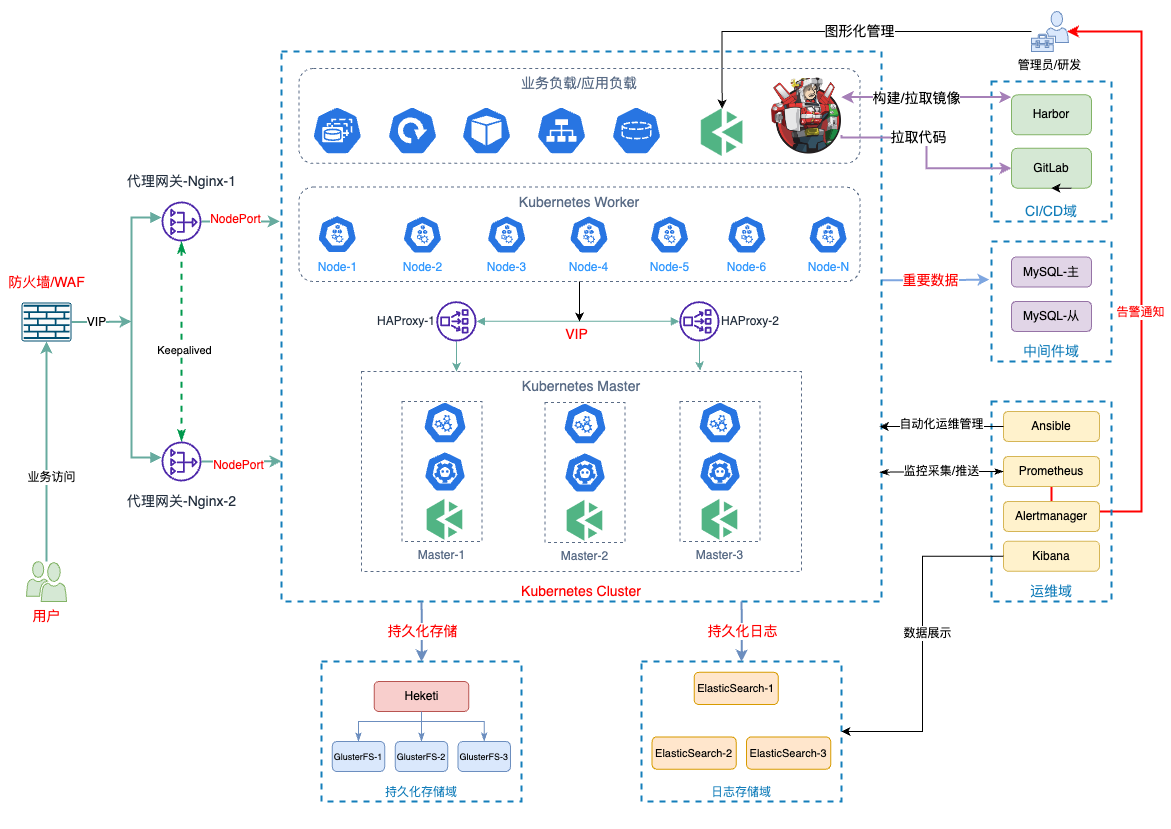
涉及软件版本
初次设计 v1.0 版时的主要软件版本:
操作系统版本:centos7.9
kubesphere: v3.1.1
KubeKey版本:v1.1.1
Kubernetes版本:v1.20.4
docker版本:v19.03.15
GlusterFS:9.4
ElasticSearch:7.15
2023 年 8 月 适用的软件版本:
操作系统版本: CentOS7.9
KubeSphere: v3.2.1(生产不建议用 3.3.x、3.4.x 系列)
KubeKey: v3.0.10(老版本也行,只要支持 KubeSphere v3.2.x 和 Kubernetes v1.24.x 即可)
Kubernetes:v1.24.x
Containerd:1.6.4(替换掉 Docker)
GlusterFS:9.6(按理说应该用 10.x,不知为何 CentOS 的源里居然没有)
ElasticSearch:8.x(选最新的就行)
网络规划
我们网络要求比较多。因此,根据不同功能模块,规划了不同的网段方便安全策略的控制。各位可根据需求合理规划,所有节点都放在一个网段也可以。
| 功能域 | 网段 | 说明 |
|---|---|---|
| 代理网关 | 192.168.8.0/24 | 代理网关作为南北向流量的转发节点,一定要和其他组件放在不同的网段 |
| K8s 集群 | 192.168.9.0/24 | K8s 集群内部节点使用 |
| 存储集群 | 192.168.10.0/24 | 持久化存储、日志存储域节点使用 |
| 中间件集群 | 192.168.11.0/24 | 独立在 K8s 集群外的,各种中间件节点使用 |
部署架构设计说明
整体的部署架构设计采用了传统的分层、分域的思想(只是这思想被我乱用的分层有点多)概要为如下 10 层/域:
- 用户访问层(最终用户)
- 防火墙/WAF 等安全设备层(本文没有介绍,云上必备,内部可选)
- 代理网关层
- 负载均衡层
- Kubernetes 集群域
- 持久化存储域
- 日志存储域
- CI/CD 域
- 中间件域(在 K8s 集群之外,独立部署)
- 运维域
用户访问层
泛指最终用户(无论从哪个渠道入口访问平台实际业务的用户)。
防火墙等安全设备层
安全是重中之重,所有上线的业务,安全设备是必不可少的,本架构设计里只提到了防火墙、WAF,实际使用中应该还有更多,这个只能大家根据需求自行组合了。
因为,安全设备层不在我的职责范围内,我只能说必须有,但是很多细节我也说不清,索性就不过多介绍了。
代理网关层规划
在代理网关的选择上,第一版选择了利用 Nginx 自建的方案,并没有选择 Ingress、Istio 等高级方案(刚接触并不熟悉没敢用)。
采用 2 台服务器部署典型的 Nginx + KeepAlived 服务,实现高可用的 7 层流量转发网关,根据域名判断规则将流量转入后端 K8s 集群节点对应的 NodePort。
该方案的优点就是对于新手比较友好,部署、维护、配置比较简单,因为都是比较熟悉的属于运维必备的玩法了。缺点就是配置文件的变更、同步都需要人工操作(最多加点自动化手段),有出错的风险。
负载均衡层规划
负载均衡属于 Kubernetes 集群内部使用,有三种可选方案。
- 采用公有云或是私有云平台上自带的弹性负载均衡服务(建议选择,很多云服务商内部的 SLB 是免费的)
需要配置监听器监听相应的服务端口
| 服务端口 | 协议 | 端口 |
|---|---|---|
| apiserver | TCP | 6443 |
| ks-console | TCP | 30880 |
| http | TCP | 80 |
| https | TCP | 443 |
- 采用 HAProxy 或是 Nginx 自建负载均衡(此次选择)
本架构设计由于某些原因,采用了 HAProxy 自建负载均衡的方案, 部署了 2 个 HAProxy 节点,并使用 Keepalived 实现 VIP 故障切换保证了高可用。
这样的选择也增加了成本,毕竟 2 台 2C 4G 配置的机器一年的成本也有几千块,重点是还要自己部署维护。
所以,在公有云的场景下还是使用服务商提供的弹性负载均衡服务(SLB)比较好,内部使用的免费而且还不需要自己维护。
- 使用 KubeKey 自带的解决方案部署 HAProxy
从版本 v1.2.1 开始,KubeKey 提供了内置高可用模式,支持一键部署高可用集群环境。
KubeKey 的高可用模式实现方式称作本地负载均衡模式。具体表现为 KubeKey 会在每一个工作节点上部署一个负载均衡器(HAproxy),所有主节点的 Kubernetes 组件连接其本地的 kube-apiserver ,而所有工作节点的 Kubernetes 组件通过由 KubeKey 部署的负载均衡器反向代理到多个主节点的 kube-apiserver 。这种模式相较于专用到负载均衡器来说效率有所降低,因为会引入额外的健康检查机制,但是如果当前环境无法提供外部负载均衡器或者虚拟 IP(VIP)时这将是一种更实用、更有效、更方便的高可用部署模式。
目前,这种部署模式用的人也很多,他们给出的理由是部署简单。更多细节可以参考使用 KubeKey 内置 HAproxy 创建高可用集群。
本架构方案初始设计时 KubeKey v1.1.1 并不支持该方式,个人建议生产环境不要用这种方案,而是采用独立部署的全局负载均衡器。
K8s 集群层规划
Kubernetes 集群初始部署采用 3 Master 和 N Worker 的架构,这样即实现了 Kubernetes 控制平面的高可用,也能满足前期业务部署对资源的需求,而且也有利于后期的升级扩容。
- Master 节点:3 节点,部署 KubeSphere 和 Kubernetes 的管理组件、Etcd 等服务。
注意:本方案并没有把 Etcd 单独部署,有条件或是规模较大的场景可以单独部署 Etcd。
- Worker 节点:前期选择 6 个节点,部署业务应用。各位可以根据实际需求决定初始化数量,但是,建议最少 3 个,后期扩容的时候增加节点的数量也是以 3 的倍数为单位。
Kubernetes 组件的高可用架构图如下:
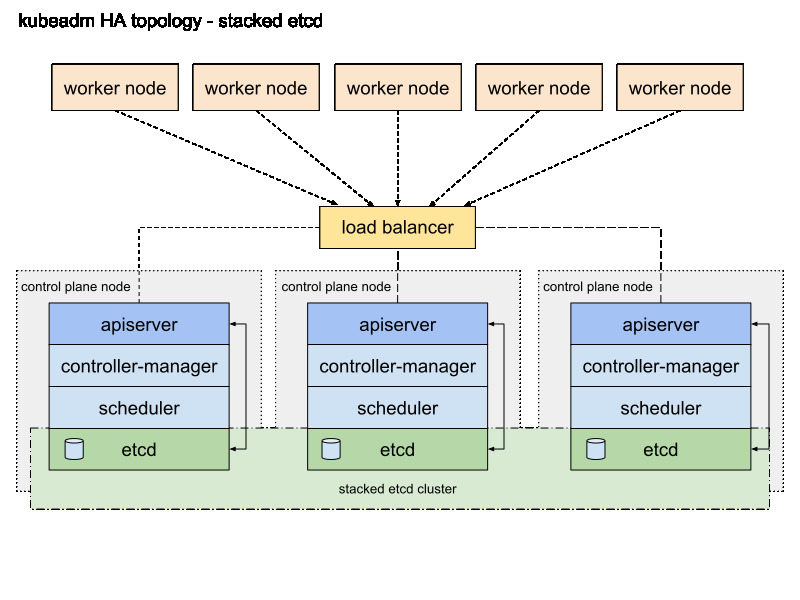
这里,需要多说一句,不知道从何时开始互联网流行了一种 2 Master 的部署架构。从我做架构设计的经验来看,不建议各位使用 2M 的架构,毕竟既然考虑了高可用架构那么一定要顾及 Etcd,2 节点的 Etcd 怎么玩高可用?
2M 的架构也只是解决了 Kube 组件的高可用,还是要找其他节点复用解决 Etcd 高可用的问题 。如果资源实在紧张可以选择 3 Master 复用为 Worker 的部署架构,也千万不要用 2M 的架构。
如果一定要用 2M 的架构,那么只适用一个场景,那就是 Etcd 采取独立节点部署的方案。
持久化存储域规划
本架构设计选择了使用 GlusterFS 作为 Kubernetes 集群的持久化存储。
3 个存储节点,安装部署 GlusterFS,其中一个节点安装 Heketi 作为管理端。
每个节点 1T 数据盘。
存储组件架构图:
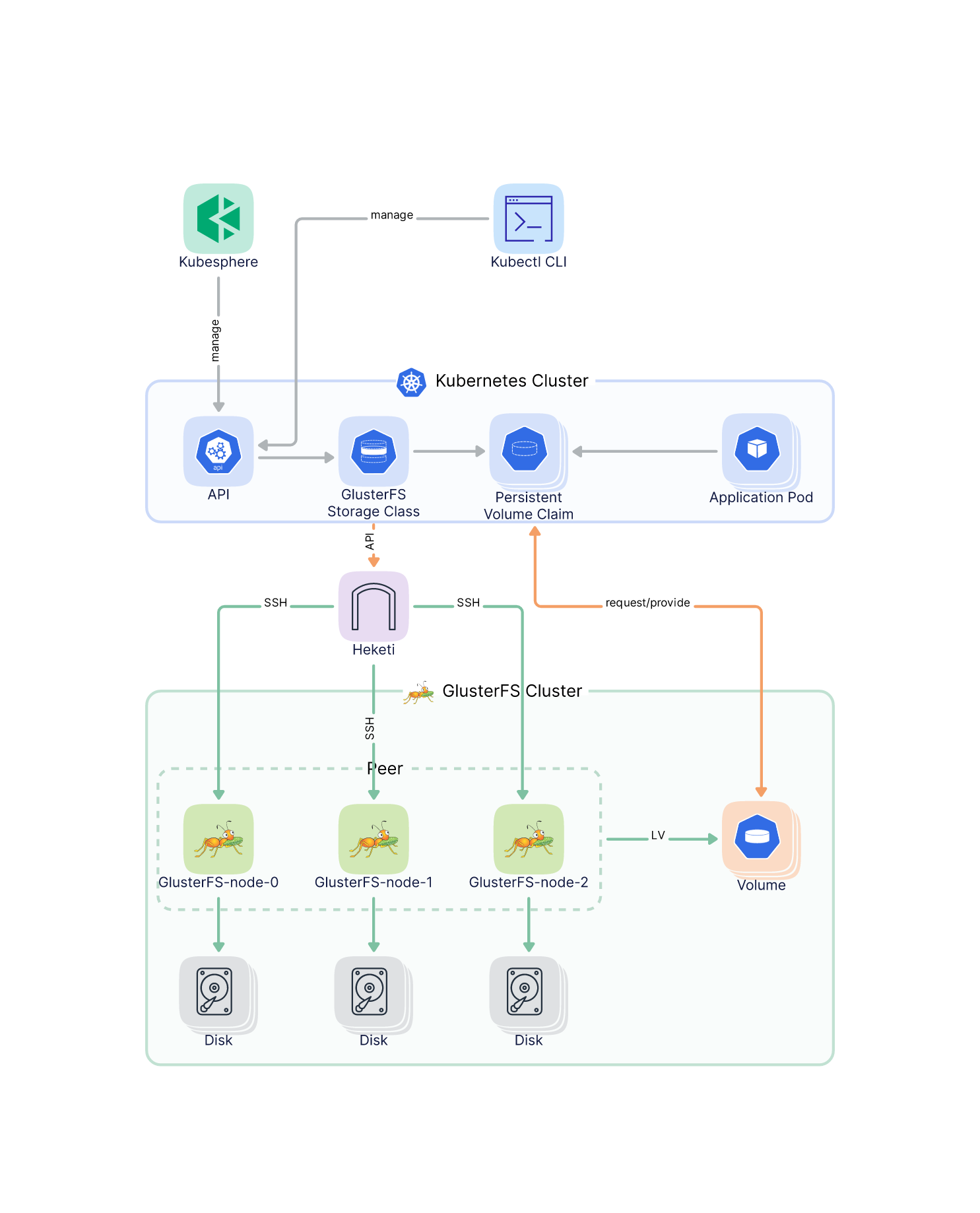
存储选型说明:
持久化存储候选者
存储方案 优点 缺点 说明 Ceph 资源多 没有 Ceph 集群故障处理能力,最好不要碰 曾经,经历过 3 副本全部损坏数据丢失的惨痛经历,因此没有能力处理各种故障之前不会再轻易选择 GlusterFS 部署、维护简单;多副本高可用 资料少 部署和维护简单,出了问题找回数据的可能性大一些 NFS 使用广泛 单点、网络抖动 据说生产环境用的很多,但是单点和网络抖动风险,隐患不小,暂不考虑 Longhorn 官宣企业级云原生容器存储解决方案,还未实践 第一季入选者
GlusterFS
说明
GlusterFS + Heketi 的存储解决方案,属于第一次做架构设计的尝试,属于摸着石头过河,也由于以前有过 GlusterFS 的运维经验,所以先用着,后期根据运行情况再重新调整。
大家请根据自己的存储需求和团队运维能力选择适合的方案,有技术实力的团队还是尽量选择 Ceph 吧。
因为我们的业务场景对于持久化存储的需求也就是存放一些 Log 日志,能承受一定的数据损失,也是选择 GlusterFS 的原因之一。
存储规划中假设 1T 数据满足需求,没考虑扩容,后续会做补充。
本次选型使用的是 Heketi 的对接方案,使用比较广泛,网上的参考用例比较多,但是该方案也存在一定弊端,各位需要根据自己的情况选择。
实现形式在底层创建了一堆的 LVM 卷,如果卷太多又太小的话,后期运维会比较麻烦,有一定的未知风险。
Heketi 项目官方已经停止更新了,项目处于维护状态(2023 年 7 月,该项目已经归档了),这就比较麻烦了,新入坑者慎入。
日志存储域规划
日志存储选择了普遍使用的 ElasticSearch 作为日志存储方案,主要用于 KubeSphere 日志、事件等插件采集的日志数据的存储。
实际部署中采用了 3 个节点部署 ElasticSearch,利用 3 副本实现数据的可靠性。KubeSphere 使用启用用户名和密码认证的 HTTP 协议去连接 ElasticSearch 存取数据。
由于不好预估日志规模,在磁盘空间规划上每个机器初期都分配了 1T 的数据盘。最后,我发现实际使用中 30 多个业务模块,日志按要求保留 180 天的场景下,500G 都用不了。
同时,初期在运维管理域部署了 Kibana 连接 ElasticSearch,实现可视化管理。后期,将 Kibana 移到了 K8s 集群上,使用 Helm 的方式部署。
CI/CD 域规划
CI/CD 并没有使用太复杂的功能,主要使用了 KubeSphere 内嵌的 DevOps 插件,利用 Jenkins 流水线实现了应用自动构建、镜像上传、自动发布、审核发布等功能。
主要包含以下组件:
- Jenkins,使用 KubeSphere 定制的 DevOps 插件(在 Kubernetes 集群上部署 Jenkins 及相应的构建任务容器)。
- GitLab,开发代码、运维代码管理,实现 GitOps(在 K8s 集群外使用虚拟机独立部署)。
- Harbor,镜像仓库(在 K8s 集群外与 GitLab 在一台虚拟机上独立部署)。
中间件域规划
有一些数据或是服务,在做架构设计时觉得部署在 K8s 集群上不靠谱,所以采用了在 K8s 集群外部的虚拟机上独立部署。
早期的规划是包含 MySQL、RabbitMQ、RocketMQ、Redis 等组件的,后来只独立部署了 MySQL,其他组件均安排到了 Kubernetes 之上。
独立部署主从复制模式的 MySQL 数据库,适合中小规模使用。大规模需要专业运维人员或是使用云上成熟的产品,有条件建议使用云服务商的 RDS 产品。
多说一句,中间件的选型上如果是在公有云环境,最好对比一下云上产品,如果成本差不多,更建议选择云上的成熟产品。
运维管理域规划
监控、告警、自动化运维、其他运维辅助工具都规划在了运维管理域,机器的分配可以根据实际情况规划。
主要包含以下组件:
- Ansible,自动化运维管理工具,执行日常批量运维管理操作。
- Prometheus、Alertmanager,用于实现 K8s 集群和集群上部署的业务应用组件的监控和告警(初期计划是自己搭建,后来发现 KubeSphere 集成的也挺好用,就暂时放弃了自建)。
- Kibana,对接 ElasticSearch,实现数据可视化管理。
部署节点规划
先看一眼总数,整个集群使用了 23 台虚拟机,120 核 CPU、464GB 内存、920GB 系统盘、12500GB 数据。
接下来我们详细说一下每一层的节点如何规划部署。规划中没有包含防火墙、WAF 等网络设备。
代理网关节点规划
| 节点角色 | 主机名 | CPU(核) | 内存(GB) | 系统盘(GB) | 数据盘(GB) | IP | 备注 |
|---|---|---|---|---|---|---|---|
| Nginx 代理 | nginx-1 | 2 | 4 | 40 | 192.168.8.2/192.168.8.1 | 自建域名网关,暂时未采用 Ingress | |
| Nginx 代理 | nginx-2 | 2 | 4 | 40 | 192.168.8.3/192.168.8.1 | 自建域名网关,暂时未采用 Ingress | |
| 合计 | 2 | 4 | 8 | 80 |
Kubernetes 集群节点规划
| 节点角色 | 主机名 | CPU(核) | 内存(GB) | 系统盘(GB) | 数据盘(GB) | IP |
|---|---|---|---|---|---|---|
| 负载均衡 | k8s-slb-1 | 2 | 4 | 40 | 192.168.9.2/192.168.9.1 | |
| 负载均衡 | k8s-slb-2 | 2 | 4 | 40 | 192.168.9.3/192.168.9.1 | |
| Master | k8s-master-1 | 8 | 32 | 40 | 500 | 192.168.9.4 |
| Master | k8s-master-2 | 8 | 32 | 40 | 500 | 192.168.9.5 |
| Master | k8s-master-3 | 8 | 32 | 40 | 500 | 192.168.9.6 |
| Worker | k8s-node-1 | 8 | 32 | 40 | 500 | 192.168.9.7 |
| Worker | k8s-node-2 | 8 | 32 | 40 | 500 | 192.168.9.8 |
| Worker | k8s-node-3 | 8 | 32 | 40 | 500 | 192.168.9.9 |
| Worker | k8s-node-4 | 8 | 32 | 40 | 500 | 192.168.9.10 |
| Worker | k8s-node-5 | 8 | 32 | 40 | 500 | 192.168.9.11 |
| Worker | k8s-node-6 | 8 | 32 | 40 | 500 | 192.168.9.12 |
| 合计 | 11 | 76 | 296 | 440 | 4500 |
重点说明:由于初次上线怕资源不够,Master 节点的配置有点多,实际使用中 4C 16G 足够了(第二版的架构设计中已经改正了)。
存储节点规划
存储节点包含持久化存储和日志存储节点:
| 节点角色 | 主机名 | CPU(核) | 内存(GB) | 系统盘(GB) | 数据盘(GB) | IP | 备注 |
|---|---|---|---|---|---|---|---|
| 存储节点 | storage-1 | 4 | 16 | 40 | 1000 | 192.168.10.1 | |
| 存储节点 | storage-2 | 4 | 16 | 40 | 1000 | 192.168.10.2 | |
| 存储节点 | storage-3 | 4 | 16 | 40 | 1000 | 192.168.10.3 | |
| 日志存储节点 | elastic-1 | 4 | 16 | 40 | 1000 | 192.168.10.4 | |
| 日志存储节点 | elastic-2 | 4 | 16 | 40 | 1000 | 192.168.10.5 | |
| 日志存储节点 | elastic-3 | 4 | 16 | 40 | 1000 | 192.168.10.6 | |
| 合计 | 6 | 24 | 96 | 240 | 6000 |
中间件节点规划
| 节点角色 | 主机名 | CPU(核) | 内存(GB) | 系统盘(GB) | 数据盘(GB) | IP | 备注 |
|---|---|---|---|---|---|---|---|
| MySQL-主 | db-master | 4 | 16 | 40 | 500 | 192.168.11.2/192.168.11.1 | 数据盘可以选高 IO 的 SSD |
| MySQL-从 | db-slave | 4 | 16 | 40 | 500 | 192.168.11.3/192.168.11.1 | 数据盘可以选高 IO 的 SSD |
| 配置管理 | Harbor | 4 | 16 | 40 | 500 | 192.168.11.10 | 安装 GitLab 和 Harbor (配置可缩) |
| Prometheus | monitor | 4 | 16 | 40 | 500 | 192.168.11.11 | 安装 Ansible,用于自动化运维 |
| 合计 | 4 | 16 | 64 | 160 | 2000 |
上面的节点资源配置规划,多少有几点不合理的地方,或者可以说是可以优化改进的地方,欢迎各位在评论区留言讨论。
成本分析
回顾一下汇总的资源总数,整个集群使用了 23 台虚拟机,120 核 CPU、464GB 内存、920GB 系统盘(不要钱)、12500GB 数据。
看着这些汇总数据,我自己都有点害怕,降本增效的当下,这有点多啊(实际上还是有优化空间的,差不多能减下去三分之一)。
接下来我们根据节点规划详细算算账,这到底要花费多少?
货比三家,特意选了三家公有云服务商,用官方提供的价格计算器算了算公开报价(所有报价均为 2023 年 8 月报价)。
有三点需要特别注意:
- 规划中没有包含防火墙、WAF 等网络设备。
- 本报价只是公开报价成本,仅供参考(渠道不同,各大云平台折扣也不同。)。
- 为了对比报价成本,所有选型都用的参数类似的产品,实际使用中请根据需求调整,例如,CPU、硬盘的调整。
计算节点类型汇总及成本分析
配置规格汇总:
| 配置类型 | 数量 |
|---|---|
| 2C 4G | 4 |
| 4C 16G | 10 |
| 8C 32G | 9 |
| 合计 | 23 |
公开报价汇总:
| 公有云平台 | 2C 4G(单价) | 2C 4G(4台总价 ) | 4C 16G(单价) | 4C 16G(10 台总价) | 8C 32G(单价) | 8C 32G(9 台总价) | 备注 |
|---|---|---|---|---|---|---|---|
| 阿里云 | 2,386.80 | 9,547.20 | 5,902.80 | 59,028.00 | 11,662.80 | 104,965.20 | 北京、通用型 g6(计算型)、系统盘(高效云盘) |
| 华为云 | 1,661.50 | 6,646.00 | 4,279.60 | 42,796.00 | 8,419.10 | 75,771.90 | 北京、通用计算 S6、系统盘(高 IO) |
| 天翼云 | 1,734.00 | 6,936.00 | 4,610.40 | 46,104.00 | 9,057.60 | 81,518.40 | 北京、通用型、系统盘(高 IO) |
说明:阿里云只有计算型里有 2C 4G 的配置。
数据盘类型汇总及成本分析
因为,系统盘不用额外算钱,包含在计算资源之内(实际上在云主机选择的时候可以选择硬盘大小,大小不同价格也不同)。所以,我们只给数据盘买单。磁盘类型设计方案中使用了统一的高 IO 类型,实际中请根据服务需要选择。
磁盘规格汇总:
| 数据盘规格 | 数量 |
|---|---|
| 500G | 13 |
| 1000G | 6 |
| 合计 | 19 |
公开报价汇总:
| 公有云平台 | 500G(单价) | 500G(13 块总价) | 1000G(单价) | 1000G(6 块总价) | 备注 |
|---|---|---|---|---|---|
| 阿里云 | 2,146.20 | 27,900.60 | 4,292.40 | 25,754.40 | 北京、高效云盘、0.245/时(500G) |
| 华为云 | 1,750.00 | 22,750.00 | 3,500.00 | 21,000.00 | 北京、高 IO |
| 天翼云 | 2,040.00 | 26,520.00 | 4,080.00 | 24,480.00 | 北京、高 IO |
总成本合计分析
| 云平台 | 计算资源总价(人民币/元/年) | 存储资源总价(人民币/元/年) | 最终总价 |
|---|---|---|---|
| 阿里云 | 173,540.40 | 53,655.00 | 227,195.40 |
| 华为云 | 125,213.90 | 43,750.00 | 168,963.90 |
| 天翼云 | 134,558.40 | 51,000.00 | 185,558.40 |
综合算下来,这套架构使用的云上资源成本多少还是有点费钱的,预计公开报价总成本最少需要人民币 168,963.90 元/年。作为一个合格的运维架构师,架构设计中成本考虑是一个重要因素,要是拿不到很好的折扣价,老板估计要干掉我了。至于实际价格就各凭本事喽!!!
总结
本文分享了我设计的第一版基于 KubeSphere 部署 Kubernetes 集群的部署架构规划方案, 此方案是一个真实的小规模生产环境部署架构设计的案例,该生产环境基于 KubeSphere v3.1.1 和 Kubernetes v1.20.4 已经稳定运行了将近 2 年,运行期间只遇到过 3 个重大问题。
- 到一年期的时候更换证书(运维不当,证书到期后才发现,手工用命令更换证书,重启相关服务后解决)。
- GlusterFS 存储扩容 1T 硬盘(直接添加新硬盘,使用 Hekiti 扩容即可)。
- ElasticSearch 无法写入数据(这个是因为索引最大值配置造成的,更该配置后解决)。
除上述 3 个问题之外,在运维得当的前提下,并没有发现其他重大故障。
概括一下,本文主要从以下几个方面介绍了第一版的部署架构设计方案:
- 整个集群的部署架构图。
- 所有涉及的主要软件的版本。
- 网络规划设计。
- 部署架构分层设计思想及 10 层规划的详细说明(本文核心价值)。
- 部署节点规划及成本分析。
这套部署架构设计方案是我设计的第一套 Kubernetes 生产环境部署方案,多少会有一些不合适的地方,比如 Master 节点资源分配过多、数据盘分配的过大、ElacticSearch 是否需要高可用等。其它读者觉得不合理的地方,也欢迎评论区留言或是私信我讨论交流。
所以,此架构方案运行的生产环境的持续运维中,我也根据出现的问题结合监控数据等可视化数据做了总结分析,设计了第二版的部署架构,也会在后期整理分享给大家,请持续关注哟!!!
